使用 Pandas AI 進行數據分析
原由
今天我的工作夥伴推來了一個客戶的一個需求,由於他們的平台需要經常性接收來自來自第三方平台的報表匯入,並且每個平台上的資料內欄位不同, 所以導致若有User上傳了一些不受支援的第三方平台的報表時,為了符合平台資料庫設計的資料庫欄位,就變得需要由工程師額外介入處理調整,因為這個原因,他們期望調整匯入的資料欄位格式的工作能簡化到是由一般行政人員甚至使用者就能單獨完成。
原本想從Python 的 Pandas套件入手,然後偶然的情況下,在逛GitHub的時候發現Pandas AI這個套件,它結合了人工智慧和資料處理技術,可以透過AI有效地分析和理解大量的資料,以下是簡易的筆記,以及用簡單的範例所做的練習。
安裝 Pandas AI
官方GitHub
官方使用說明文件
安裝 Pandas AI Python庫
安裝其他額外依賴項(非必須)
以下是可替換extra-dependency-name的選項(結至2023/11/04官方支援安裝的依賴項):
- google-aip:若使用Google PaLM作為語言模型,則需要此額外依賴。
- google-sheet:若使用Google Sheets作為數據來源,則需要此額外依賴。
- excel:若使用Excel文件作為數據來源,則需要此額外依賴。
- polars:若使用Polars數據框作為數據來源,則需要此額外依賴。
- langchain:若想支援LangChain LLMs,則需要此額外依賴。
- numpy:若想支援numpy,則需要此額外依賴。
- ggplot:若想支援ggplot繪圖,則需要此額外依賴。
- seaborn:若想支援seaborn繪圖,則需要此額外依賴。
- plotly:若想支援plotly繪圖,則需要此額外依賴。
- statsmodels:若想支援statsmodels,則需要此額外依賴。
- scikit-learn:若想支援scikit-learn,則需要此額外依賴。
- streamlit:若想支援streamlit,則需要此額外依賴。
建立 OpenAI API key
- 連結 https://platform.openai.com/ 註冊OpenAI帳戶
- 註冊完後,連結 https://platform.openai.com/account/api-keys
- 點選Create new secret key 按鈕
- 設定 API Key Name (非必須)
- 複製畫面上顯示的API Key(只會顯示一次)的內容,以便Pandas AI使用
下載測試用數據集
檔案來源:https://ourworldindata.org/grapher/national-gdp-constant-usd-wb?tab=table
該資料為的資料範圍為1960年至2021年各國國內生產毛額(GDP)
確認測試用數據集的資料狀況
確認資料狀況
先用pandas寫一段簡單的載入csv的code,看一下資料長了什麼樣子。
import pandas as pd
#載入csv檔案
df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv')
df
 由上圖所示,這份csv檔案有四個欄位
* Entity欄位代表國家名稱
* Code 欄位代表國家代碼
* Year 欄位代表某的GDP收入的年份
* GDP (constant 2015 US$) 欄位代表某年份的GDP收入
由上圖所示,這份csv檔案有四個欄位
* Entity欄位代表國家名稱
* Code 欄位代表國家代碼
* Year 欄位代表某的GDP收入的年份
* GDP (constant 2015 US$) 欄位代表某年份的GDP收入
檢查以及清洗不需要的數據
接著使用sort_values 排序一下GDP (constant 2015 US$) 這個欄位
import pandas as pd
#載入csv檔案
df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv')
#根據GDP由大到小排序
df.sort_values('GDP (constant 2015 US$)',ascending=False).head(10)
 所以估計是Entity 參雜全球GDP總收入的資料,所以再用drop函數把Entity=World 的列刪除後,再排序一下GDP (constant 2015 US$) 這個欄位
所以估計是Entity 參雜全球GDP總收入的資料,所以再用drop函數把Entity=World 的列刪除後,再排序一下GDP (constant 2015 US$) 這個欄位
import pandas as pd
#載入csv檔案
df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv')
#刪除Entity=World的資料
df.drop(df[df['Entity'] == "World"].index, inplace = True)
#根據GDP由大到小排序
df.sort_values('GDP (constant 2015 US$)',ascending=False).head(10)
 不過仔細一看,發現似乎當Code=NaN的情況下才會出現Entity 欄位為非國家名稱的內容,所以我用dropna函數,把的列刪除後,再排序一下GDP (constant 2015 US$) 這個欄位
不過仔細一看,發現似乎當Code=NaN的情況下才會出現Entity 欄位為非國家名稱的內容,所以我用dropna函數,把的列刪除後,再排序一下GDP (constant 2015 US$) 這個欄位
import pandas as pd
#載入csv檔案
df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv')
#刪除Entity=World的資料
df.drop(df[df['Entity'] == "World"].index, inplace = True)
#刪除Code=NaN的資料
df = df.dropna(subset=["Code"])
#根據GDP由大到小排序
df.sort_values('GDP (constant 2015 US$)',ascending=False).head(10)
 (已經剔除所有不需要進行操作的資料)
(已經剔除所有不需要進行操作的資料)
最後整份csv的狀況
- Entity 有不是國家名稱的資料的內容
- 需要剔除Entity=World以及Code=NaN
期望下,希望所有動作都能直接透過AI進行完成而不用人工進行干預,但是就以實務狀況而言,絕大部分都需要事先以人工介入的了解整份資料,來確保有哪些列或者欄位是不用參與統計,然後再告訴AI哪些部分是需要處理的。
使用Pandas AI剔除掉不需要的資料
在上面,已經了解整份資料的狀況,得知需要剔除資料的條件為Entity=World以及Code=NaN,現在就讓用AI的方式進行資料剔除,然後再來比較傳統方式篩選以及以及使用AI的方式篩選資料的兩者是否一致
'''
使用傳統的方式篩選資料
'''
import pandas as pd
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
#載入csv檔案
df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv')
#刪除Entity=World的資料
df.drop(df[df['Entity'] == "World"].index, inplace = True)
#刪除Code=NaN的資料
df = df.dropna(subset=["Code"])
df
'''
使用AI的方式篩選資料
'''
import pandas as pd
from pandasai import SmartDataframe
from pandasai.llm import OpenAI
#載入csv檔案
df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv')
#設定OpenAI API Key
llm = OpenAI(api_token="your-open-ai-key") #改成你的openAI ApiKey
sdf = SmartDataframe(df, config={"llm": llm})
#執行指令
sdf.chat('篩選出Entity!=World以及Code!=NaN的所有欄位資料')
 透過這兩張圖,可以很清楚看的出來兩種方式的篩選結果是相同的 😜
透過這兩張圖,可以很清楚看的出來兩種方式的篩選結果是相同的 😜
💡使用AI方式進行篩選,最好是要給它明確的指令,才能得到正確結果,以下是個錯誤的例子
''' 使用AI的方式篩選資料 ''' import pandas as pd from pandasai import SmartDataframe from pandasai.llm import OpenAI #載入csv檔案 df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv') #設定OpenAI API Key llm = OpenAI(api_token="your-open-ai-key") #改成你的openAI ApiKey sdf = SmartDataframe(df, config={"llm": llm}) #執行指令 sdf.chat('篩選出Entity不是國家名稱的所有欄位資料')(錯誤的篩選結果) 📌簡單來說,平常是以什麼樣的邏輯撰寫篩選資料的code,就把這個過程敘述給AI知道,基本上它會給你滿意的答案 ✌🏽
使用Agent進行數據複雜探索
PandasAI中的SmartDataframe或SmartDatalake主要適用於單個對話和探索性數據分析,而Agent則可用於多輪對話,所以相較與其他兩個相比,會更加具備彈性,接下來定義一些篩選的場景,一樣比較傳統方式篩選以及以及使用AI的方式篩選資料的兩者是否一致。
範例1
❓列出每個國家2002年GDP的資料,並取只取GDP前10名的國家
''' 使用傳統的方式篩選資料 ''' import pandas as pd #載入csv檔案 df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv') #刪除Entity=World的資料 df.drop(df[df['Entity'] == "World"].index, inplace = True) #刪除Code=NaN的資料 df = df.dropna(subset=["Code"]) #資料篩選 df[df['Year'] == 2002].sort_values('GDP (constant 2015 US$)',ascending=False).head(10)''' 使用AI的方式篩選資料 ''' import pandas as pd from pandasai import Agent from pandasai.llm import OpenAI #載入csv檔案 df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv') #設定OpenAI API Key llm = OpenAI(api_token="your-open-ai-key") #改成你的openAI ApiKey #使用agent agent = Agent([df],config={"llm": llm}) #開始篩選 agent.chat('篩選出Entity!=World以及Code!=NaN的所有欄位資料') agent.chat('從篩選的資料裡,只列出2002年資料') agent.chat('並且根據GDP由大到小排序') agent.chat('然後只顯示前10筆資料')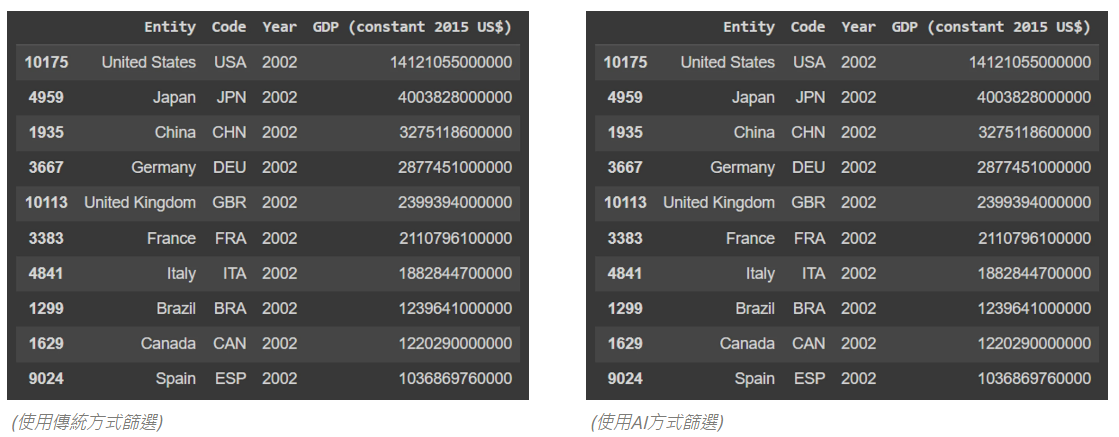
範例2
❓計算每個國家的GDP總額,並取只取GDP排行前10名的國家
''' 使用傳統的方式篩選資料 ''' import pandas as pd #載入csv檔案 df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv') #刪除Entity=World的資料 df.drop(df[df['Entity'] == "World"].index, inplace = True) #刪除Code=NaN的資料 df = df.dropna(subset=["Code"]) #分組並篩選資料 df.groupby(['Entity'])['Entity', 'GDP (constant 2015 US$)'].sum(["GDP"]).sort_values('GDP (constant 2015 US$)',ascending=False).head(10) Copy '''''' 使用AI的方式篩選資料 ''' import pandas as pd from pandasai import SmartDataframe from pandasai import Agent from pandasai.llm import OpenAI #載入csv檔案 df = pd.read_csv('/content/703f1019-d248-4d44-82c2-0438f0697f93.csv') #設定OpenAI API Key llm = OpenAI(api_token="your-open-ai-key") #改成你的openAI ApiKey #使用代理 agent = Agent([df],config={"llm": llm}) agent.chat('篩選出Entity!=World以及Code!=NaN的所有欄位資料') agent.chat('然後資料欄位僅保留Entity,Code,GDP (constant 2015 US$)這三個欄位') agent.chat('從篩選的資料裡,根據國家進行分組,統計GDP總額') agent.chat('並且根據GDP由大到小排序') agent.chat('最後只顯示前10筆資料')😜可以看出兩種方式的所得到的結果是相同的
使用Pandas AI 分析資料來源為Google 試算表的資料
資料來源若要使用Google Sheet,需要額外安裝google-sheet 依賴項,安裝指令如下
⚠️使用Google 試算表作為資料來源,須確保該資料來源的狀態是”公開” 接下來寫個簡單的程式碼測試一下,我將上面各國國內生產毛額(GDP)的資料轉傳一份到Google Drive上,可以使用這個連結測試
import pandas as pd from pandasai import Agent from pandasai.llm import OpenAI #設定OpenAI API Key llm = OpenAI(api_token="your-open-ai-key") #改成你的openAI ApiKey #使用代理 agent = Agent("https://docs.google.com/spreadsheets/d/e/2PACX-1vSI7onT003iRJr1EtU4UmF22B67r4KPbaVOrHrkoFUn0uOiAgDUWurquy9uQ0qugmHNYxFA4Acke8PY/pubhtml?gid=1709359405",config={"llm": llm}) agent.chat('篩選出Entity!=World以及Code!=""的所有欄位資料') #Code 改為 != "" 是因為Google 試算表會將NaN值轉成空字串 agent.chat('然後資料欄位僅保留Entity,Code,GDP (constant 2015 US$)這三個欄位') agent.chat('從篩選的資料裡,根據國家進行分組,統計GDP總額') agent.chat('並且根據GDP由大到小排序') agent.chat('最後只顯示前10筆資料')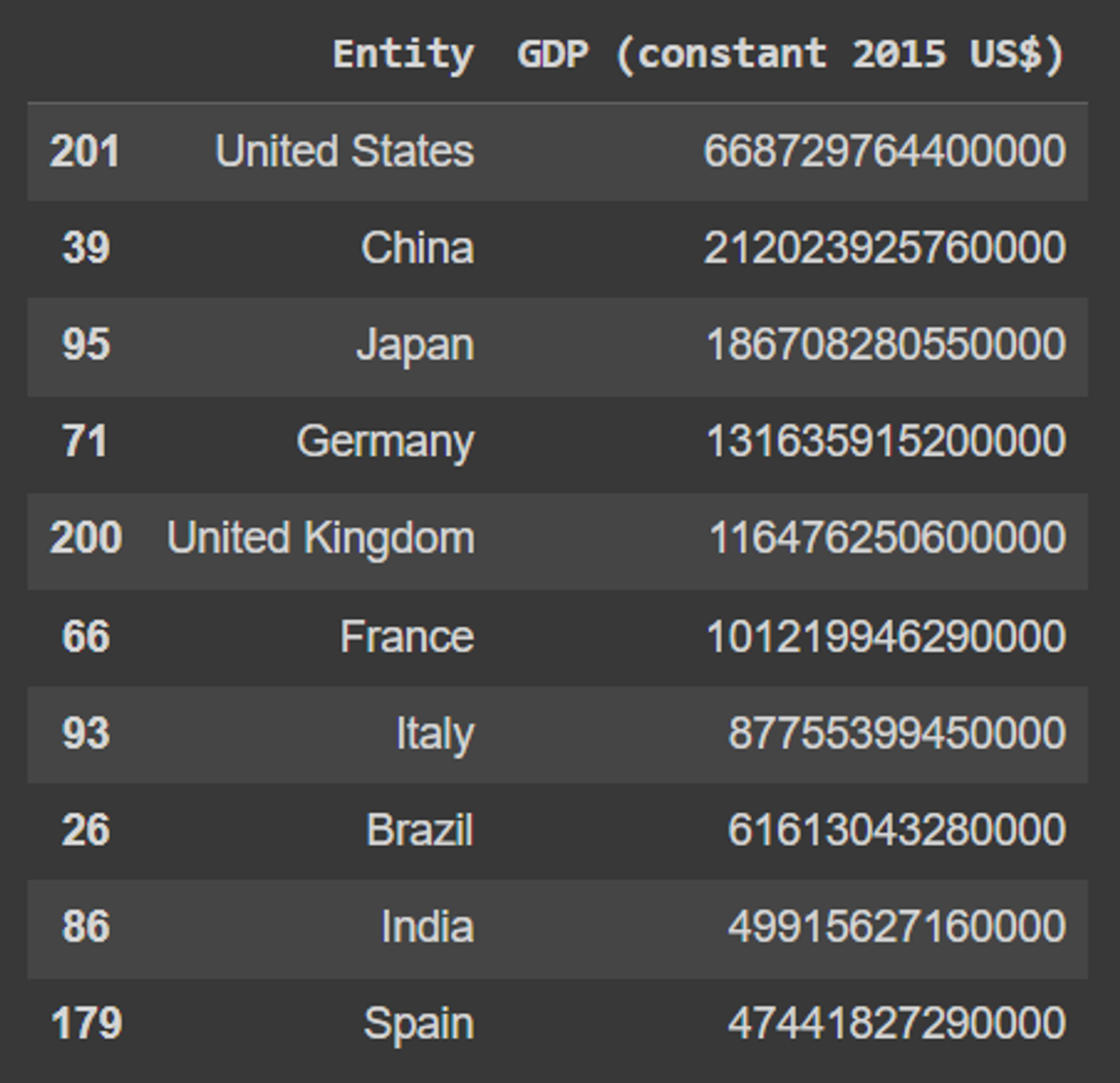
每次 OpenAI 大約會消耗的Token數
 每次調用OpenAI的所使用的Token數量大約會在1000個Token左右
每次調用OpenAI的所使用的Token數量大約會在1000個Token左右
💡Pandas AI 在每次調用AI時,預設會包含元數據和五筆的示例用資料當作提示文,如果資料為敏感性的資料,可以透過config中的enforce_privacy參數改為True,這樣就會只發送元數據的資料了
PS.enforce_privacy設定為True可能會降低準確度 😌